数据处理工具-信息熵
工具简介
信息熵能表征信息的不确定度,是一种用来衡量信息量多少的统计量。在一个随机事件中,某个事件发生的不确定性越大,为了解清楚它是否发生所需要的信息量就越大,即信息熵就越大。随机性越大的系统(内部数据分布越均匀的系统),由于各种事情都可能发生,要消除系统的不确定性所需要的信息也就越多,信息熵与系统的组织结构密切相关,因此可以通过熵的变化来观察系统的变化,信息熵可以度量系统结构的有序程度。
①选择要计算信息熵的文件的类型及文件

选择文件类型:选择需要进行信息熵计算的文件类型,可以是空间文件,也可以是属性表格文件。
选择空间文件:在下拉框下拉选择需要格进行信息熵计算的文件。
②选择需要进行信息熵计算的字段

选择计算字段:选择用于计算信息熵的属性值字段名,至少选择两个字段。
③设置输出文件的名称,并提交运行

设置输出文件名称:给输出的文件命名,若不设置名称,将自动命名为“工具名称_时间”。
完成设置后,点击“提交运行”启动工具。
运行成功后页面上方将会提示“完成计算!”,可点击前往我的数据界面按钮到数据页面查看启动访问数据。
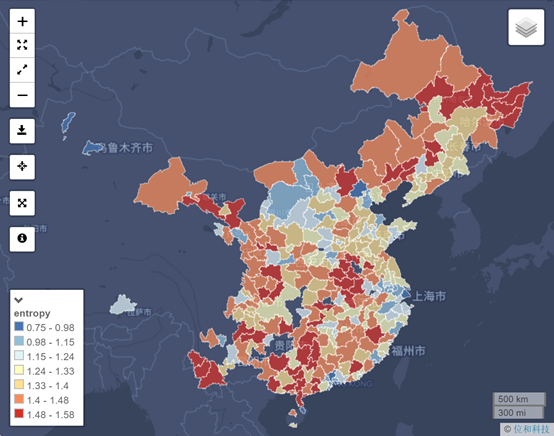
如下图为计算全国2016年各城市第一、第二、第三产业占比三个属性值的信息熵结果。信息熵可以度量产业结构,当三个产业处于均衡状态时,信息熵高。通过计算全国各城市三大产业占比的信息熵,可以反映不同地区产业分布的均衡程度。